NAMA : Merdeka Putra
NPM : 56414592
KELAS : 4IA22
IMPLEMENTASI CLOUD COMPUTING MENGGUNAKAN MODEL INFRASTRUCTURE AS A SERVICE UNTUK OPTIMALISASI LAYANAN DATA CENTER (Studi Kasus : UPT STMIK AMIKOM YOGYAKARTA)
Penulis : Danang Setiyawan
ABSTRAK
Laboratorium komputer pada UPT STMIK AMIKOM Yogyakarta berjumlah banyak dan kapasitas pengguna yang besar maka kebutuhan layanan data center juga semakin tinggi. Untuk memenuhi kebutuhan pengembangan data center tersebut dibutuhkan peningkatan kapasitas komputasi, salah satunya adalah dengan cara pengadaan server baru. Namun terdapat konsekuensi dari keputusan tersebut, organisasi akan menghadapi beberapa masalah baru dalam pengelolaan server yang semakin bertambah yaitu biaya yang dihabiskan untuk keperluan tersebut cukup besar. Biaya yang paling besar adalah pada pembelian dan maintenance server. Pemanfaatan fungsi server juga digunakan untuk mendukung pembelajaran praktikum di laboratorium komputer, jadi selain biaya dan maintenance organisasi juga akan menghadapi permasalahan baru, yaitu utilisasi server yang rendah. Untuk itu cloud computing sebagai solusi yang tepat untuk di implementasikan di laboratorium komputer STMIK AMIKOM Yogyakarta agar layanan data center bisa optimal dari sisi jumlah layanan dan penggunaan sumberdaya server.
kata Kunci : Data center, server, maintenance, utilisasi, cloud computing
PENDAHULUAN
Laboratorium komputer yang dimiliki STMIK AMIKOM Yogyakarta merupakan aset dan fasilitas terbesar dan dikelola oleh bagian UPT dengan jumlah empat belas ruang dengan berbagai spesifikasi perangkat dan platform Operating System. Infrastruktur jaringan laboratorium komputer sudah menggunakan perangkat dengan kecepatan gigabit ethernet dan memanfaatkan sistem Data Terpusat (data center) yang digunakan untuk menampung tugas atau project praktikum yang dikerjakan oleh mahasiswa. Layanan utama yang diberikan oleh data center adalah layanan file server berbasis web dan file sharing yang berjalan pada protokol Microsoft SMB Protocol.
Dengan jumlah laboratorium komputer yang banyak serta kapasitas pengguna yang besar maka kebutuhan layanan data center juga semakin tinggi. Untuk memenuhi kebutuhan pengembangan data center tersebut dibutuhkan peningkatan kapasitas komputasi, salah satunya adalah dengan cara pengadaan server baru. Namun terdapat konsekuensi dari keputusan tersebut, organisasi akan menghadapi beberapa masalah baru dalam pengelolaan server yang semakin bertambah yaitu biaya yang dihabiskan untuk keperluan tersebut cukup besar. Biaya yang paling besar adalah pada pembelian dan maintenance server. Selain biaya dan maintenance organisasi juga akan menghadapi permasalahan baru, yaitu utilisasi server yang rendah . (Suryono & Afif, 2013). Permasalahan yang lain adalah pemanfaatan fungsi-fungsi server untuk mendukung pembelajaran praktikum di laboratorium komputer.
Dengan permasalahan yang dihadapi, cloud computing menggunakan model infrastructure as a service sebagai solusi yang sesuai untuk di implementasikan dengan tujuan untuk optimalisasi layanan data center di UPT STMIK AMIKOM Yogyakarta.
Pada penelitian ini model cloud computing yang digunakan adalah model IaaS dan infrastruktur cloud yang digunakan adalah private cloud dan hanya membahas pada fitur aplikasi cloud computing
METODE PENELITIAN
Metodologi penelitian yang dilakukan dalam pelaksanaan penelitian ini yaitu :
1. Tahap Studi Literatur
2. Tahap Analisa, Desain dan Implementasi
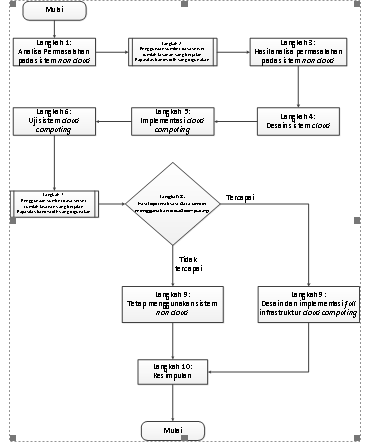
Dibawah ini merupakan gambar dari hasil analisa dan desain cloud computing.
HASIL DAN PEMBAHASAN
Pengujian yang dijalankan pada system cloud terdiri dari beberapa bagian scenario yang dijalankan pada server virtualisasi. Skenario pengujian dijalankan pada native server dan cloud server yang diimplementasikan pada server yang identic. Pengukuran metric skalabilitas menggunakan metode overhead dan linieritas.
1. Topologi yang diusulkan
Topologi dedicated
Non-dedicated
2. Pengujian Server Cloud
1. Analisa Overhead
a. Analisa overhead pada skenario pengujian pertama
Analisa pertama mendapatkan hasil sebagai berikut :
Dari hasil pengujian pada skenario pertama didapatkan hasil bahwa durasi waktu transfer
native server lebih cepat dibandingkan dengan cloud server. Pengguna utilitas server
sebesar 9.19%.
Dibawah ini grafis durasi Upload file per cloud
b. Analisa overhead pada skenario pengujian kedua
Analisa kedua mendapatkan hasil sebagai berikut :
Dari hasil pengujian pada skenario kedua didapatkan durasi waktu transfer lebih tinggi
dibanding native server. Pengguna utilitas server sebesar 20.72%.
Dibawah ini grafi durasi Upload file per cloud
Perbandingan durasi transfer file pada pengujian overhead antara scenario pertama dan
kedua
Hasil nilai degradasi server ketika menjalankan sepuluh cloud server sebesar :
3. Analisa Linearitas
a. Analisa linearitas pada scenario pengujian pertama
Mendapatkan hasil perbandingan sebagai berikut :
b. Analisa linearitas pada scenario pengujian kedua
Mendapatkan hasil perbandingan sebagai berikut :
Berikut adalah grafis pengukuran linearitas pada Cloud Server
Hasil pengukuran yang diperoleh dari linearitas adalah
n = 10
tmax = ov + t x n, dimana ov = 300 ms
t = 13.29 sec
= 13290 ms
Maka tmax = 300 + 13290 x 10
= 133200 ms
4. Analisis Data Skalabilitas Server Virtual
Pengukuran yang telah dilakukan diperoleh nilai Overhead sebagai berikut :
Ta = 12.9
Ov = 0.39 sec
= 390 ms
Ovn = 3.34 sec
= 3340 ms
Degradasi kinerja server setelah sepuluh cloud server dijalankan : 11,67%.
A. Pengukuran Penggunaan Sumber Daya pada Server Native dan Server Virtual
Hasil pengukuran yang diperoleh ketika user-user telah terhubung ke jaringan namun
server belum menjalankan program aplikasi dapat dijelaskan pada tabel berikut:
Berikut grafik sumber daya maksimum perangkat keras
PEMBAHASAN
Berdasarkan hasil observasi diatas dapat dilihat bahwa pada setiap penambahan server cloud pada pengujian overhead penggunaan sumber daya server terlihat stabil walaupun ketika dilihat hasil observasi secara terperinci, terdapat fluktuasi ketika server cloud dijalankan. Pada pengujian overhead, penggunaan utilitas cpu pada server cloud terlihat lebih tinggi jika dibandingkan dengan utilitas cpu pada native server. Nilai tertinggi pada server cloud didapatkan pada server NS.
Pada pengujian linearitas skenario pertama dan skenario kedua hasil yang didapatkan tampak tidak ada peningkatan yang signifikan jika dibandingkan dengan pengujian overhead di skenario yang sama. Utitilitas cpu pada native server mendapatkan hasil yang sama dengan pengujian overhead.
Pada pengujian waktu eksekusi di masing-masing server cloud, durasi waktu startup jika dibandingkan dengan native server hasil yang didapatkan lebih pendek dengan perbandingan sesuai dengan tabel berikut:
KELEBIHAN DAN KEKURANGAN
Cloud Computing memiliki kelebihan dan kekurangan. Kelebihannya adalah teknologi yang murah dan juga dapa hasil yang optimal. Server mampu menjalankan lebih dari satu virtual server, kemudahan administrator untuk menkonfigurasi sumber daya server untuk virtual server, Dengan penggunaan cloud computing akan lebih efektif jika sistem penyimpanan menggunakan data terpusat.
Kekurangannya terdapat pada durasi waktu transfer file pada server cloud lebih lambat jika dibandingkan dengan waktu transfer file pada native server dan membutuhkan kapasitas RAM yang besar untuk menjaga kestabilan server cloud.
KESIMPULAN
Setelah melakukan ujicoba untuk implementasi cloud computing menggunakan model infrastructure as a service untuk optimalisasi layanan data center, beberapa kesimpulan bisa didapat antara lain:
- Dari hasil pengukuran dan analisa didapatkan hasil bahwa optimalisasi layanan data center di UPT STMIK AMIKOM Yogyakarta dapat tercapai. Hal ini dibuktikan dengan satu server mampu menjalankan lebih dari satu virtual server.
- Dari data yang didapatkan, durasi waktu transfer file pada server cloud lebih lambat jika dibandingkan dengan waktu transfer file pada native server. Hal ini dikarenakan masing-masing server cloud harus berbagi sumberdaya dalam melakukan akses input dan output.
- Pada perbandingan analisa hasil pengukuran overhead, nilai overhead relatif stabil pada setiap tipe server cloud. Jika dilihat secara terperinci, terdapat fluktuasi pada beberapa titik ketika menjalankan server cloud.
- Jika menggunakan dan menjalankan lebih banyak service pada server cloud, semakin banyak inti prosesor dan semakin besar kapasitas RAM yang digunakan akan lebih baik dalam kestabilan server cloud secara keseluruhan.